Calculating diversity and mutation
Calculating mutational load
To calculate mutational load, the functions from immcantation suite’s shazam [Gupta2015] can be accessed via rpy2 to work with the dandelion class object.
This can be run immediately after pp.reassign_alleles during the reannotation pre-processing stage because the required germline columns should be present in the genotyped .tsv file. I would recommend to run this after TIgGER [Gadala-Maria2015], after the v_calls were corrected. Otherwise, if the reannotation was skipped, you can run it now as follows:
Import modules
[1]:
import os
import dandelion as ddl
import matplotlib.pyplot as plt
import pandas as pd
import polars as pl
import seaborn as sns
import scanpy as sc
sc.settings.verbosity = 3
# change to tutorials directory
os.chdir("dandelion_tutorial")
Read in the previously saved files
[2]:
adata = sc.read_h5ad("adata.h5ad")
adata
[2]:
AnnData object with n_obs × n_vars = 25063 × 1309
obs: 'sample_id', 'n_genes', 'n_genes_by_counts', 'total_counts', 'total_counts_mt', 'pct_counts_mt', 'gmm_pct_count_clusters_keep', 'scrublet_score', 'is_doublet', 'filter_rna', 'has_contig', 'productive_VDJ', 'productive_VJ', 'd_call_VDJ', 'j_call_VDJ', 'j_call_VJ', 'junction_VDJ', 'junction_VJ', 'junction_aa_VDJ', 'junction_aa_VJ', 'locus_VDJ', 'locus_VJ', 'v_call_VDJ', 'v_call_VJ', 'c_call_VDJ', 'c_call_VJ', 'umi_count_VDJ', 'umi_count_VJ', 'productive_VDJ_main', 'productive_VJ_main', 'd_call_VDJ_main', 'j_call_VDJ_main', 'j_call_VJ_main', 'junction_VDJ_main', 'junction_VJ_main', 'junction_aa_VDJ_main', 'junction_aa_VJ_main', 'locus_VDJ_main', 'locus_VJ_main', 'v_call_genotyped_VDJ_main', 'v_call_genotyped_VJ_main', 'c_call_VDJ_main', 'c_call_VJ_main', 'umi_count_VDJ_main', 'umi_count_VJ_main', 'isotype', 'isotype_main', 'isotype_status', 'locus_status', 'chain_status', 'rearrangement_status_VDJ', 'rearrangement_status_VJ', 'leiden', 'clone_id', 'clone_id_rank'
var: 'n_cells', 'highly_variable', 'means', 'dispersions', 'dispersions_norm', 'mean', 'std'
uns: 'chain_status_colors', 'clone_id', 'dandelion', 'gex_neighbors', 'hvg', 'isotype_status_colors', 'leiden', 'leiden_colors', 'locus_status_colors', 'log1p', 'neighbors', 'pca', 'sample_id_colors', 'umap'
obsm: 'X_pca', 'X_umap', 'X_vdj'
varm: 'PCs'
obsp: 'connectivities', 'distances'
Note
This tutorial will be trying to quantify mutations in the BCR data, and this function requires access to IMGT-formatted VDJ gene calls with allelic information. So if you have ran vdj.simplify before this tutorial, then it would not work. Therefore, we are loading in the DandelionPolars object without simplified calls.
[3]:
vdj = ddl.read_zipddl("dandelion_results.zipddl")
vdj
[3]:
Lazy Dandelion object with n_obs = 2496 and n_contigs = 5792
data: sequence_id, sequence, rev_comp, productive, v_call, d_call, j_call, sequence_alignment, germline_alignment, junction, junction_aa, v_cigar, d_cigar, j_cigar, stop_codon, vj_in_frame, locus, junction_length, np1_length, np2_length, v_sequence_start, v_sequence_end, v_germline_start, v_germline_end, d_sequence_start, d_sequence_end, d_germline_start, d_germline_end, j_sequence_start, j_sequence_end, j_germline_start, j_germline_end, v_score, v_identity, v_support, d_score, d_identity, d_support, j_score, j_identity, j_support, fwr1, fwr2, fwr3, fwr4, cdr1, cdr2, cdr3, cell_id, consensus_count, umi_count, v_call_10x, d_call_10x, j_call_10x, junction_10x, junction_10x_aa, j_call_blastn, j_identity_blastn, j_alignment_length_blastn, j_number_of_mismatches_blastn, j_number_of_gap_openings_blastn, j_sequence_start_blastn, j_sequence_end_blastn, j_germline_start_blastn, j_germline_end_blastn, j_support_blastn, j_score_blastn, j_sequence_alignment_blastn, j_germline_alignment_blastn, j_call_igblastn, j_source, j_support_igblastn, j_score_igblastn, d_call_blastn, d_identity_blastn, d_alignment_length_blastn, d_number_of_mismatches_blastn, d_number_of_gap_openings_blastn, d_sequence_start_blastn, d_sequence_end_blastn, d_germline_start_blastn, d_germline_end_blastn, d_support_blastn, d_score_blastn, d_sequence_alignment_blastn, d_germline_alignment_blastn, d_call_igblastn, d_source, d_support_igblastn, d_score_igblastn, v_call_genotyped, germline_alignment_d_mask, sample_id, c_call, c_sequence_alignment, c_germline_alignment, c_sequence_start, c_sequence_end, c_score, c_identity, c_call_10x, junction_aa_length, fwr1_aa, fwr2_aa, fwr3_aa, fwr4_aa, cdr1_aa, cdr2_aa, cdr3_aa, sequence_alignment_aa, v_sequence_alignment_aa, d_sequence_alignment_aa, j_sequence_alignment_aa, complete_vdj, j_call_multimappers, j_call_multiplicity, j_call_sequence_start_multimappers, j_call_sequence_end_multimappers, j_call_support_multimappers, mu_count, rearrangement_status, v_call_functionality, d_call_functionality, j_call_functionality, extra, ambiguous
metadata: cell_id, sample_id, productive_VDJ, productive_VJ, d_call_VDJ, j_call_VDJ, j_call_VJ, junction_VDJ, junction_VJ, junction_aa_VDJ, junction_aa_VJ, locus_VDJ, locus_VJ, v_call_VDJ, v_call_VJ, c_call_VDJ, c_call_VJ, umi_count_VDJ, umi_count_VJ, productive_VDJ_main, productive_VJ_main, d_call_VDJ_main, j_call_VDJ_main, j_call_VJ_main, junction_VDJ_main, junction_VJ_main, junction_aa_VDJ_main, junction_aa_VJ_main, locus_VDJ_main, locus_VJ_main, v_call_genotyped_VDJ_main, v_call_genotyped_VJ_main, c_call_VDJ_main, c_call_VJ_main, umi_count_VDJ_main, umi_count_VJ_main, isotype, isotype_main, isotype_status, locus_status, chain_status, rearrangement_status_VDJ, rearrangement_status_VJ
[4]:
# let's rerun the find_clones and generate network steps again so we can visualise the data
ddl.tl.find_clones(vdj)
ddl.tl.generate_network(vdj)
Finding clonotypes
Using PyTorch backend with Apple Metal GPU
Finding clones based on B cell VDJ chains using junction_aa: 100%|██████████| 1248/1248 [00:01<00:00, 737.16it/s]
Finding clones based on B cell VJ chains using junction_aa: 100%|██████████| 579/579 [00:00<00:00, 886.99it/s]
Storing distance matrix...
Building distance matrix (batched): 100%|██████████| 19/19 [00:00<00:00, 3497.71it/s]
Stored distances as CSR sparse matrix: (2496, 2496), density=0.59%
finished: Updated Dandelion object:
'data', contig AIRR table
'metadata', cell observations table
'distances', sparse distance matrix
(0:00:03)
Generating network
Using pre-computed distances from .distances
Computing network layout
OMP: Info #276: omp_set_nested routine deprecated, please use omp_set_max_active_levels instead.
Computing expanded network layout
finished.
Updated Dandelion object
: 'layout', graph layout
(0:00:00)
[5]:
# let's recreate the vdj object with only the first two samples
subset_data = vdj.data[
vdj.data["sample_id"].is_in(
["sc5p_v2_hs_PBMC_1k_b", "sc5p_v2_hs_PBMC_10k_b"]
)
]
subset_data.collect()
[5]:
| sequence_id | sequence | rev_comp | productive | v_call | d_call | j_call | sequence_alignment | germline_alignment | junction | junction_aa | v_cigar | d_cigar | j_cigar | stop_codon | vj_in_frame | locus | junction_length | np1_length | np2_length | v_sequence_start | v_sequence_end | v_germline_start | v_germline_end | d_sequence_start | d_sequence_end | d_germline_start | d_germline_end | j_sequence_start | j_sequence_end | j_germline_start | j_germline_end | v_score | v_identity | v_support | d_score | d_identity | … | v_call_genotyped | germline_alignment_d_mask | sample_id | c_call | c_sequence_alignment | c_germline_alignment | c_sequence_start | c_sequence_end | c_score | c_identity | c_call_10x | junction_aa_length | fwr1_aa | fwr2_aa | fwr3_aa | fwr4_aa | cdr1_aa | cdr2_aa | cdr3_aa | sequence_alignment_aa | v_sequence_alignment_aa | d_sequence_alignment_aa | j_sequence_alignment_aa | complete_vdj | j_call_multimappers | j_call_multiplicity | j_call_sequence_start_multimappers | j_call_sequence_end_multimappers | j_call_support_multimappers | mu_count | rearrangement_status | v_call_functionality | d_call_functionality | j_call_functionality | extra | ambiguous | clone_id |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| str | str | str | str | str | str | str | str | str | str | str | str | str | str | str | str | str | i64 | i64 | i64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | … | str | str | str | str | str | str | f64 | f64 | f64 | f64 | str | i64 | str | str | str | str | str | str | str | str | str | str | str | str | str | f64 | str | str | str | f64 | str | str | str | str | str | str | str |
| "sc5p_v2_hs_PBMC_10k_b_AAACCTGT… | "TGGGGAGGAGTCAGTCCCAACCAGGACACG… | "F" | "T" | "IGKV1-33*01,IGKV1D-33*01" | null | "IGKJ4*01" | "GACATCCAGATGACCCAGTCTCCATCCTCC… | "GACATCCAGATGACCCAGTCTCCATCCTCC… | "TGTCAACAATATGACGAACTTCCCGTCACT… | "CQQYDELPVTF" | "98S44=1X31=2X2=1X7=1X3=1X3=1X3… | null | "384S2N22=1X5=" | "F" | "T" | "IGK" | 33 | 2 | null | 99.0 | 382.0 | 1.0 | 332.0 | null | null | null | null | 385.0 | 412.0 | 3.0 | 30.0 | 363.0 | 0.90845 | 4.1800e-102 | null | null | … | "IGKV1-33*01,IGKV1D-33*01" | "GACATCCAGATGACCCAGTCTCCATCCTCC… | "sc5p_v2_hs_PBMC_10k_b" | "IGKC" | "CGAACTGTGGCTGCACCATCTGTCTTCATC… | "CGAACTGTGGCTGCACCATCTGTCTTCATC… | 420.0 | 556.0 | 254.0 | 100.0 | "IGKC" | 11 | "DIQMTQSPSSLSASVGDRVTITCQAT" | "VNWYQQKPGKAPKLLIY" | "NLEIGVPSRFSGRGSGTVFILTISSLQPED… | "FGGGTNVEMR" | "QDINNY" | "DAL" | "QQYDELPVT" | "DIQMTQSPSSLSASVGDRVTITCQATQDIN… | "DIQMTQSPSSLSASVGDRVTITCQATQDIN… | null | "TFGGGTNV" | null | "["IGKJ4*01"]" | 1.0 | "[385]" | "[412]" | "[3.56e-09]" | 27.0 | "Standard" | "F" | null | "F" | "F" | "F" | "B_VJ_36_2_2" |
| "sc5p_v2_hs_PBMC_10k_b_AAACCTGT… | "ATCACATAACAACCACATTCCTCCTCTAAA… | "F" | "T" | "IGHV1-69*01,IGHV1-69D*01" | "IGHD3-22*01" | "IGHJ3*02" | "CAGGTGCAGCTGGTGCAGTCTGGGGCT...… | "CAGGTGCAGCTGGTGCAGTCTGGGGCT...… | "TGTGCGACTACGTATTACTATGATAGTAGT… | "CATTYYYDSSGYYQNDAFDIW" | "115S292=" | "411S28=" | "444S50=" | "F" | "T" | "IGH" | 63 | 4 | 5 | 116.0 | 407.0 | 1.0 | 316.0 | 412.0 | 439.0 | 1.0 | 28.0 | 445.0 | 494.0 | 1.0 | 50.0 | 456.0 | 1.0 | 3.0700e-130 | 54.5 | 1.0 | … | "IGHV1-69*01,IGHV1-69D*01" | "CAGGTGCAGCTGGTGCAGTCTGGGGCT...… | "sc5p_v2_hs_PBMC_10k_b" | "IGHM" | "GGAGTGCATCCGCCCCAACCCTTTTCCCCC… | "GGAGTGCATCCGCCCCAACCCTTTTCCCCC… | 495.0 | 565.0 | 132.0 | 100.0 | "IGHM" | 21 | "QVQLVQSGAEVKKPGSSVKVSCKAS" | "ISWVRQAPGQGLEWMGG" | "NYAQKFQGRVTITADESTSTAYMELSSLRS… | "WGQGTMVTVSS" | "GGTFSSYA" | "IIPIFGTA" | "ATTYYYDSSGYYQNDAFDI" | "QVQLVQSGAEVKKPGSSVKVSCKASGGTFS… | "QVQLVQSGAEVKKPGSSVKVSCKASGGTFS… | "YYYDSSGYY" | "DAFDIWGQGTMVTVSS" | null | "["IGHJ3*02"]" | 1.0 | "[445]" | "[494]" | "[4.58e-23]" | 0.0 | "Standard" | "F" | "F" | "F" | "F" | "F" | "B_VDJ_46_3_2_VJ_60_2_1" |
| "sc5p_v2_hs_PBMC_10k_b_AAACCTGT… | "AGGAGTCAGACCCTGTCAGGACACAGCATA… | "F" | "T" | "IGKV1-8*01" | null | "IGKJ1*01" | "GCCATCCGGATGACCCAGTCTCCATCCTCA… | "GCCATCCGGATGACCCAGTCTCCATCCTCA… | "TGTCAACAGTATTATAGTTACCCTCGGACG… | "CQQYYSYPRTF" | "93S286=" | null | "379S2N36=" | "F" | "T" | "IGK" | 33 | 0 | null | 94.0 | 379.0 | 1.0 | 334.0 | null | null | null | null | 380.0 | 415.0 | 3.0 | 38.0 | 447.0 | 1.0 | 1.9500e-127 | null | null | … | "IGKV1-8*01" | "GCCATCCGGATGACCCAGTCTCCATCCTCA… | "sc5p_v2_hs_PBMC_10k_b" | "IGKC" | "CGAACTGTGGCTGCACCATCTGTCTTCATC… | "CGAACTGTGGCTGCACCATCTGTCTTCATC… | 415.0 | 551.0 | 254.0 | 100.0 | "IGKC" | 11 | "AIRMTQSPSSFSASTGDRVTITCRAS" | "LAWYQQKPGKAPKLLIY" | "TLQSGVPSRFSGSGSGTDFTLTISCLQSED… | "FGQGTKVEIK" | "QGISSY" | "AAS" | "QQYYSYPRT" | "AIRMTQSPSSFSASTGDRVTITCRASQGIS… | "AIRMTQSPSSFSASTGDRVTITCRASQGIS… | null | "TFGQGTKVEIK" | null | "["IGKJ1*01"]" | 1.0 | "[380]" | "[415]" | "[2.7e-15]" | 0.0 | "Standard" | "F" | null | "F" | "F" | "F" | "B_VDJ_46_3_2_VJ_60_2_1" |
| "sc5p_v2_hs_PBMC_10k_b_AAACCTGT… | "ACTGTGGGGGTAAGAGGTTGTGTCCACCAT… | "F" | "T" | "IGLV5-45*02" | null | "IGLJ3*02" | "CAGGCTGTGCTGACTCAGCCGTCTTCC...… | "CAGGCTGTGCTGACTCAGCCGTCTTCC...… | "TGTATGATTTGGCACAGCAGCGCTTGGGTG… | "CMIWHSSAWVV" | "85S52=1X3=1X22=1X15=1X11=1X10=… | null | "395S2N5=1X30=" | "F" | "T" | "IGL" | 33 | 0 | null | 86.0 | 395.0 | 1.0 | 334.0 | null | null | null | null | 396.0 | 431.0 | 3.0 | 38.0 | 463.0 | 0.97742 | 4.6600e-132 | null | null | … | "IGLV5-45*02" | "CAGGCTGTGCTGACTCAGCCGTCTTCC...… | "sc5p_v2_hs_PBMC_10k_b" | "IGLC3" | "GTCAGCCCAAGGCTGCCCCCTCGGTCACTC… | "GTCAGCCCAAGGCTGCCCCCTCGGTCACTC… | 432.0 | 642.0 | 390.0 | 100.0 | "IGLC3" | 11 | "QAVLTQPSSLSASPGASGRLTCTLR" | "IYWYQRKPGSPPQYLLR" | "QQGSGVPSRFSGSKDASANAGILLISGLQS… | "VGGGTKLTVL" | "SDINVGTYR" | "YKSDSDK" | "MIWHSSAWV" | "QAVLTQPSSLSASPGASGRLTCTLRSDINV… | "QAVLTQPSSLSASPGASGRLTCTLRSDINV… | null | "VVGGGTKLTVL" | null | "["IGLJ3*01"]" | 1.0 | "[402]" | "[431]" | "[6.84e-12]" | 8.0 | "Standard" | "F" | null | "F" | "F" | "F" | "B_VDJ_9_1_2_VJ_256_1_1" |
| "sc5p_v2_hs_PBMC_10k_b_AAACCTGT… | "GGGAGCATCACCCAGCAACCACATCTGTCC… | "F" | "T" | "IGHV1-2*02" | null | "IGHJ3*02" | "CAGGTGCAACTGGTGCAGTCTGGGGGT...… | "CAGGTGCAGCTGGTGCAGTCTGGGGCT...… | "TGTGCGAGAGAGATAGAGGGGGACGGTGTT… | "CAREIEGDGVFEIW" | "121S8=1X16=1X6=1X58=1X5=2X2=1X… | null | "435S6N6=1X37=" | "F" | "T" | "IGH" | 42 | 18 | null | 122.0 | 417.0 | 1.0 | 320.0 | null | null | null | null | 436.0 | 479.0 | 7.0 | 50.0 | 394.0 | 0.92568 | 1.7200e-111 | null | null | … | "IGHV1-2*02" | "CAGGTGCAGCTGGTGCAGTCTGGGGCT...… | "sc5p_v2_hs_PBMC_10k_b" | "IGHM" | "GGAGTGCATCCGCCCCAACCCTTTTCCCCC… | "GGAGTGCATCCGCCCCAACCCTTTTCCCCC… | 480.0 | 550.0 | 132.0 | 100.0 | "IGHM" | 14 | "QVQLVQSGGEVKKPGASVKVSCKAS" | "IQWLRHAPGQGLDWMGL" | "NYAQKFQGRVTMTRDTSISTAYMELSSLRS… | "WGQGTMVTVSS" | "GYTFTDYF" | "INPNSGDT" | "AREIEGDGVFEI" | "QVQLVQSGGEVKKPGASVKVSCKASGYTFT… | "QVQLVQSGGEVKKPGASVKVSCKASGYTFT… | null | "FEIWGQGTMVTVSS" | null | "["IGHJ3*02"]" | 1.0 | "[433]" | "[479]" | "[4.48e-18]" | 22.0 | "Standard" | "F" | null | "F" | "F" | "F" | "B_VDJ_9_1_2_VJ_256_1_1" |
| … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … |
| "sc5p_v2_hs_PBMC_1k_b_TTCCCAGAG… | "AGCTCTGAGAGAGGAGCCCAGCCCTGGGAT… | "F" | "T" | "IGHV3-23*01,IGHV3-23D*01" | "IGHD1-26*01" | "IGHJ4*02" | "GAGGTCCAACTGTTGGAATCTGGGGGA...… | "GAGGTGCAGCTGTTGGAGTCTGGGGGA...… | "TGTGCGAGAGTTTTTGGGTCGGTGGGAGCT… | "CARVFGSVGATRSTDYW" | "136S5=1X2=1X8=1X11=1X3=1X7=1X2… | "442S6N12=" | "463S8N40=" | "F" | "T" | "IGH" | 51 | 11 | 9 | 137.0 | 431.0 | 1.0 | 319.0 | 443.0 | 454.0 | 7.0 | 18.0 | 464.0 | 503.0 | 9.0 | 48.0 | 358.0 | 0.88814 | 1.3200e-100 | 23.8 | 1.0 | … | "IGHV3-23*01,IGHV3-23D*01" | "GAGGTGCAGCTGTTGGAGTCTGGGGGA...… | "sc5p_v2_hs_PBMC_1k_b" | "IGHG4A" | "CCTCCACCAAGGGCCCATCGGTCTTCCCCC… | "CCTCCACCAAGGGCCCATCGGTCTTCCCCC… | 504.0 | 685.0 | 337.0 | 100.0 | "IGHG2" | 17 | "EVQLLESGGGLIQPGGSLRLSCATS" | "MNWVRQAPGKGLEWVSG" | "DYTDSVKGRFTISRDNSNNTLFLQMKSLRV… | "WGQGTLVTVSS" | "GFTFNNHA" | "ISGGGGRS" | "ARVFGSVGATRSTDY" | "EVQLLESGGGLIQPGGSLRLSCATSGFTFN… | "EVQLLESGGGLIQPGGSLRLSCATSGFTFN… | "VGAT" | "DYWGQGTLVTVSS" | null | "["IGHJ4*02"]" | 1.0 | "[464]" | "[503]" | "[2.02e-17]" | 33.0 | "Standard" | "F" | "F" | "F" | "F" | "F" | "B_VDJ_102_10_11_VJ_17_1_3" |
| "sc5p_v2_hs_PBMC_1k_b_TTGAACGCA… | "AGGAGTCAGACCCTGTCAGGACACAGCATA… | "F" | "T" | "IGKV1-8*01" | null | "IGKJ1*01" | "GCCATCCGGATGACCCAGTCTCCATCCTCA… | "GCCATCCGGATGACCCAGTCTCCATCCTCA… | "TGTCAACAGTATTATAGTTACCCGTGGACG… | "CQQYYSYPWTF" | "93S284=" | null | "377S38=" | "F" | "T" | "IGK" | 33 | 0 | null | 94.0 | 377.0 | 1.0 | 332.0 | null | null | null | null | 378.0 | 415.0 | 1.0 | 38.0 | 444.0 | 1.0 | 1.6900e-126 | null | null | … | "IGKV1-8*01" | "GCCATCCGGATGACCCAGTCTCCATCCTCA… | "sc5p_v2_hs_PBMC_1k_b" | "IGKC" | "CGAACTGTGGCTGCACCATCTGTCTTCATC… | "CGAACTGTGGCTGCACCATCTGTCTTCATC… | 415.0 | 551.0 | 254.0 | 100.0 | "IGKC" | 11 | "AIRMTQSPSSFSASTGDRVTITCRAS" | "LAWYQQKPGKAPKLLIY" | "TLQSGVPSRFSGSGSGTDFTLTISCLQSED… | "FGQGTKVEIK" | "QGISSY" | "AAS" | "QQYYSYPWT" | "AIRMTQSPSSFSASTGDRVTITCRASQGIS… | "AIRMTQSPSSFSASTGDRVTITCRASQGIS… | null | "WTFGQGTKVEIK" | null | "["IGKJ1*01"]" | 1.0 | "[378]" | "[415]" | "[2.09e-16]" | 0.0 | "Standard" | "F" | null | "F" | "F" | "F" | "B_VDJ_120_11_1_VJ_60_2_1" |
| "sc5p_v2_hs_PBMC_1k_b_TTGAACGCA… | "CGAGCCCAGCACTGGAAGTCGCCGGTGTTT… | "F" | "T" | "IGHV3-30-3*01" | "IGHD3-9*01" | "IGHJ4*02" | "CAGGTGCAGCTGGTGGAGTCTGGGGGA...… | "CAGGTGCAGCTGGTGGAGTCTGGGGGA...… | "TGTGCGAGAGATGAGTTAGATATTTTGACT… | "CARDELDILTGYNIPTFGGCVYW" | "124S296=" | "427S7N17=" | "471S10N38=" | "F" | "T" | "IGH" | 69 | 7 | 27 | 125.0 | 420.0 | 1.0 | 320.0 | 428.0 | 444.0 | 8.0 | 24.0 | 472.0 | 509.0 | 11.0 | 48.0 | 463.0 | 1.0 | 4.1900e-132 | 33.4 | 1.0 | … | "IGHV3-30-3*01" | "CAGGTGCAGCTGGTGGAGTCTGGGGGA...… | "sc5p_v2_hs_PBMC_1k_b" | "IGHM" | "GGAGTGCATCCGCCCCAACCCTTTTCCCCC… | "GGAGTGCATCCGCCCCAACCCTTTTCCCCC… | 510.0 | 580.0 | 132.0 | 100.0 | "IGHM" | 23 | "QVQLVESGGGVVQPGRSLRLSCAAS" | "MHWVRQAPGKGLEWVAV" | "YYADSVKGRFTISRDNSKNTLYLQMNSLRA… | "WGQGTLVTVSS" | "GFTFSSYA" | "ISYDGSNK" | "ARDELDILTGYNIPTFGGCVY" | "QVQLVESGGGVVQPGRSLRLSCAASGFTFS… | "QVQLVESGGGVVQPGRSLRLSCAASGFTFS… | "DILTG" | "YWGQGTLVTVSS" | null | "["IGHJ4*02"]" | 1.0 | "[469]" | "[509]" | "[2.2e-16]" | 0.0 | "Standard" | "F" | "F" | "F" | "F" | "F" | "B_VDJ_120_11_1_VJ_60_2_1" |
| "sc5p_v2_hs_PBMC_1k_b_TTGCCGTAG… | "GAGCTACAACAGGCAGGCAGGGGCAGCAAG… | "F" | "T" | "IGKV4-1*01" | null | "IGKJ2*01" | "GACATCGTGATGACCCAGTCTCCAGACTCC… | "GACATCGTGATGACCCAGTCTCCAGACTCC… | "TGTCAGCAATATTATAGTACTCCGTACACT… | "CQQYYSTPYTF" | "90S302=" | null | "392S1N38=" | "F" | "T" | "IGK" | 33 | 0 | null | 91.0 | 392.0 | 1.0 | 332.0 | null | null | null | null | 393.0 | 430.0 | 2.0 | 39.0 | 472.0 | 1.0 | 6.2700e-135 | null | null | … | "IGKV4-1*01" | "GACATCGTGATGACCCAGTCTCCAGACTCC… | "sc5p_v2_hs_PBMC_1k_b" | "IGKC" | "CGAACTGTGGCTGCACCATCTGTCTTCATC… | "CGAACTGTGGCTGCACCATCTGTCTTCATC… | 430.0 | 566.0 | 254.0 | 100.0 | "IGKC" | 11 | "DIVMTQSPDSLAVSLGERATINCKSS" | "LAWYQQKPGQPPKLLIY" | "TRESGVPDRFSGSGSGTDFTLTISSLQAED… | "FGQGTKLEIK" | "QSVLYSSNNKNY" | "WAS" | "QQYYSTPYT" | "DIVMTQSPDSLAVSLGERATINCKSSQSVL… | "DIVMTQSPDSLAVSLGERATINCKSSQSVL… | null | "YTFGQGTKLEIK" | null | "["IGKJ2*01"]" | 1.0 | "[393]" | "[430]" | "[2.15e-16]" | 0.0 | "Standard" | "F" | null | "F" | "F" | "F" | "B_VDJ_65_1_1_VJ_144_2_1" |
| "sc5p_v2_hs_PBMC_1k_b_TTGCCGTAG… | "TGGGGAGTGACTCCTGTGCCCCACCATGGA… | "F" | "T" | "IGHV2-5*02" | null | "IGHJ6*02" | "CAGATCACCTTGAAGGAGTCTGGTCCT...… | "CAGATCACCTTGAAGGAGTCTGGTCCT...… | "TGTGCACACAGCGACTACTATGAGGGGCGC… | "CAHSDYYEGRGMDVW" | "82S299=" | null | "399S16N47=" | "F" | "T" | "IGH" | 45 | 18 | null | 83.0 | 381.0 | 1.0 | 320.0 | null | null | null | null | 400.0 | 446.0 | 17.0 | 63.0 | 467.0 | 1.0 | 1.4500e-133 | null | null | … | "IGHV2-5*02" | "CAGATCACCTTGAAGGAGTCTGGTCCT...… | "sc5p_v2_hs_PBMC_1k_b" | "IGHM" | "GGAGTGCATCCGCCCCAACCCTTTTCCCCC… | "GGAGTGCATCCGCCCCAACCCTTTTCCCCC… | 447.0 | 517.0 | 132.0 | 100.0 | "IGHM" | 15 | "QITLKESGPTLVKPTQTLTLTCTFS" | "VGWIRQPPGKALEWLAL" | "RYSPSLKSRLTITKDTSKNQVVLTMTNMDP… | "WGQGTTVTVSS" | "GFSLSTSGVG" | "IYWDDDK" | "AHSDYYEGRGMDV" | "QITLKESGPTLVKPTQTLTLTCTFSGFSLS… | "QITLKESGPTLVKPTQTLTLTCTFSGFSLS… | null | "GMDVWGQGTTVTVSS" | null | "["IGHJ6*02"]" | 1.0 | "[400]" | "[446]" | "[1.94e-21]" | 0.0 | "Standard" | "F" | null | "F" | "F" | "F" | "B_VDJ_65_1_1_VJ_144_2_1" |
[6]:
# create a new Dandelion class with this subset
vdj2 = ddl.Dandelion(subset_data.collect())
vdj2
[6]:
Lazy Dandelion object with n_obs = 818 and n_contigs = 1899
data: sequence_id, sequence, rev_comp, productive, v_call, d_call, j_call, sequence_alignment, germline_alignment, junction, junction_aa, v_cigar, d_cigar, j_cigar, stop_codon, vj_in_frame, locus, junction_length, np1_length, np2_length, v_sequence_start, v_sequence_end, v_germline_start, v_germline_end, d_sequence_start, d_sequence_end, d_germline_start, d_germline_end, j_sequence_start, j_sequence_end, j_germline_start, j_germline_end, v_score, v_identity, v_support, d_score, d_identity, d_support, j_score, j_identity, j_support, fwr1, fwr2, fwr3, fwr4, cdr1, cdr2, cdr3, cell_id, consensus_count, umi_count, v_call_10x, d_call_10x, j_call_10x, junction_10x, junction_10x_aa, j_call_blastn, j_identity_blastn, j_alignment_length_blastn, j_number_of_mismatches_blastn, j_number_of_gap_openings_blastn, j_sequence_start_blastn, j_sequence_end_blastn, j_germline_start_blastn, j_germline_end_blastn, j_support_blastn, j_score_blastn, j_sequence_alignment_blastn, j_germline_alignment_blastn, j_call_igblastn, j_source, j_support_igblastn, j_score_igblastn, d_call_blastn, d_identity_blastn, d_alignment_length_blastn, d_number_of_mismatches_blastn, d_number_of_gap_openings_blastn, d_sequence_start_blastn, d_sequence_end_blastn, d_germline_start_blastn, d_germline_end_blastn, d_support_blastn, d_score_blastn, d_sequence_alignment_blastn, d_germline_alignment_blastn, d_call_igblastn, d_source, d_support_igblastn, d_score_igblastn, v_call_genotyped, germline_alignment_d_mask, sample_id, c_call, c_sequence_alignment, c_germline_alignment, c_sequence_start, c_sequence_end, c_score, c_identity, c_call_10x, junction_aa_length, fwr1_aa, fwr2_aa, fwr3_aa, fwr4_aa, cdr1_aa, cdr2_aa, cdr3_aa, sequence_alignment_aa, v_sequence_alignment_aa, d_sequence_alignment_aa, j_sequence_alignment_aa, complete_vdj, j_call_multimappers, j_call_multiplicity, j_call_sequence_start_multimappers, j_call_sequence_end_multimappers, j_call_support_multimappers, mu_count, rearrangement_status, v_call_functionality, d_call_functionality, j_call_functionality, extra, ambiguous, clone_id
metadata: cell_id, clone_id, clone_id_rank, sample_id, productive_VDJ, productive_VJ, d_call_VDJ, j_call_VDJ, j_call_VJ, junction_VDJ, junction_VJ, junction_aa_VDJ, junction_aa_VJ, locus_VDJ, locus_VJ, v_call_VDJ, v_call_VJ, c_call_VDJ, c_call_VJ, umi_count_VDJ, umi_count_VJ, productive_VDJ_main, productive_VJ_main, d_call_VDJ_main, j_call_VDJ_main, j_call_VJ_main, junction_VDJ_main, junction_VJ_main, junction_aa_VDJ_main, junction_aa_VJ_main, locus_VDJ_main, locus_VJ_main, v_call_genotyped_VDJ_main, v_call_genotyped_VJ_main, c_call_VDJ_main, c_call_VJ_main, umi_count_VDJ_main, umi_count_VJ_main, isotype, isotype_main, isotype_status, locus_status, chain_status, rearrangement_status_VDJ, rearrangement_status_VJ
store_germline_reference
We can store the corrected germline fasta files (after running TIgGER) in the DandelionPolars class as a dictionary.
[7]:
# update the germline using the corrected files after tigger
vdj2.store_germline_reference(
corrected="tutorial_scgp1/tutorial_scgp1_heavy_igblast_db-pass_genotype.fasta",
germline=None,
org="human",
)
Updating germline reference
finished: Updated Dandelion object:
'germline', updated germline reference
(0:00:00)
pp.create_germlines
Then we run pp.create_germline to (re)create the germline_alignment_d_mask column in the data. This works by calling CreateGermlines.py with only -d and -r options. Add further arguments with additional_args like below for your needs. See https://changeo.readthedocs.io/en/stable/examples/germlines.html for more info.
Note
In order for this function to work, the V/D/J calls need to be in IMGT format with allelic information. So if you have ran vdj.simplify before this step, then it would not work.
[8]:
ddl.pp.create_germlines(vdj2, additional_args=["--vf", "v_call_genotyped"])
Reconstructing germline sequences
Running command: CreateGermlines.py -d /private/var/folders/_r/j_8_fj3x28n2th3ch0ckn9c40000gt/T/tmpb9dobon2/tmp.tsv -r /var/folders/_r/j_8_fj3x28n2th3ch0ckn9c40000gt/T/tmpb9dobon2/germ.fasta --vf v_call_genotyped
START> CreateGermlines
FILE> tmp.tsv
GERM_TYPES> dmask
SEQ_FIELD> sequence_alignment
V_FIELD> v_call_genotyped
D_FIELD> d_call
J_FIELD> j_call
CLONED> False
PROGRESS> 13:58:50 |####################| 100% (1,899) 0.0 min
OUTPUT> tmp_germ-pass.tsv
RECORDS> 1899
PASS> 1899
FAIL> 0
END> CreateGermlines
finished: Returning DandelionPolars object:
(0:00:02)
[8]:
Lazy Dandelion object with n_obs = 818 and n_contigs = 1899
data: sequence_id, sequence, rev_comp, productive, v_call, d_call, j_call, sequence_alignment, germline_alignment, junction, junction_aa, v_cigar, d_cigar, j_cigar, stop_codon, vj_in_frame, locus, junction_length, np1_length, np2_length, v_sequence_start, v_sequence_end, v_germline_start, v_germline_end, d_sequence_start, d_sequence_end, d_germline_start, d_germline_end, j_sequence_start, j_sequence_end, j_germline_start, j_germline_end, v_score, v_identity, v_support, d_score, d_identity, d_support, j_score, j_identity, j_support, fwr1, fwr2, fwr3, fwr4, cdr1, cdr2, cdr3, cell_id, consensus_count, umi_count, c_call, c_sequence_alignment, c_germline_alignment, c_sequence_start, c_sequence_end, c_score, c_identity, junction_aa_length, fwr1_aa, fwr2_aa, fwr3_aa, fwr4_aa, cdr1_aa, cdr2_aa, cdr3_aa, sequence_alignment_aa, v_sequence_alignment_aa, d_sequence_alignment_aa, j_sequence_alignment_aa, complete_vdj, clone_id, v_call_10x, d_call_10x, j_call_10x, junction_10x, junction_10x_aa, j_call_blastn, j_identity_blastn, j_alignment_length_blastn, j_number_of_mismatches_blastn, j_number_of_gap_openings_blastn, j_sequence_start_blastn, j_sequence_end_blastn, j_germline_start_blastn, j_germline_end_blastn, j_support_blastn, j_score_blastn, j_sequence_alignment_blastn, j_germline_alignment_blastn, j_call_igblastn, j_source, j_support_igblastn, j_score_igblastn, d_call_blastn, d_identity_blastn, d_alignment_length_blastn, d_number_of_mismatches_blastn, d_number_of_gap_openings_blastn, d_sequence_start_blastn, d_sequence_end_blastn, d_germline_start_blastn, d_germline_end_blastn, d_support_blastn, d_score_blastn, d_sequence_alignment_blastn, d_germline_alignment_blastn, d_call_igblastn, d_source, d_support_igblastn, d_score_igblastn, v_call_genotyped, germline_alignment_d_mask, sample_id, c_call_10x, j_call_multimappers, j_call_multiplicity, j_call_sequence_start_multimappers, j_call_sequence_end_multimappers, j_call_support_multimappers, mu_count, rearrangement_status, v_call_functionality, d_call_functionality, j_call_functionality, extra, ambiguous
metadata: cell_id, clone_id, clone_id_rank, sample_id, productive_VDJ, productive_VJ, d_call_VDJ, j_call_VDJ, j_call_VJ, junction_VDJ, junction_VJ, junction_aa_VDJ, junction_aa_VJ, locus_VDJ, locus_VJ, c_call_VDJ, c_call_VJ, v_call_VDJ, v_call_VJ, umi_count_VDJ, umi_count_VJ, productive_VDJ_main, productive_VJ_main, d_call_VDJ_main, j_call_VDJ_main, j_call_VJ_main, junction_VDJ_main, junction_VJ_main, junction_aa_VDJ_main, junction_aa_VJ_main, locus_VDJ_main, locus_VJ_main, c_call_VDJ_main, c_call_VJ_main, v_call_genotyped_VDJ_main, v_call_genotyped_VJ_main, umi_count_VDJ_main, umi_count_VJ_main, isotype, isotype_main, isotype_status, locus_status, chain_status, rearrangement_status_VDJ, rearrangement_status_VJ
Ensure that the germline_alignment_d_mask column is populated or subsequent steps will fail.
[9]:
vdj2.data[["v_call_genotyped", "germline_alignment_d_mask"]].collect()
[9]:
| v_call_genotyped | germline_alignment_d_mask |
|---|---|
| str | str |
| "IGKV1-33*01,IGKV1D-33*01" | "GACATCCAGATGACCCAGTCTCCATCCTCC… |
| "IGHV1-69*01,IGHV1-69D*01" | "CAGGTGCAGCTGGTGCAGTCTGGGGCT...… |
| "IGKV1-8*01" | "GCCATCCGGATGACCCAGTCTCCATCCTCA… |
| "IGLV5-45*02" | "CAGGCTGTGCTGACTCAGCCGTCTTCC...… |
| "IGHV1-2*02" | "CAGGTGCAGCTGGTGCAGTCTGGGGCT...… |
| … | … |
| "IGHV3-23*01,IGHV3-23D*01" | "GAGGTGCAGCTGTTGGAGTCTGGGGGA...… |
| "IGKV1-8*01" | "GCCATCCGGATGACCCAGTCTCCATCCTCA… |
| "IGHV3-30-3*01" | "CAGGTGCAGCTGGTGGAGTCTGGGGGA...… |
| "IGKV4-1*01" | "GACATCGTGATGACCCAGTCTCCAGACTCC… |
| "IGHV2-5*02" | "CAGATCACCTTGAAGGAGTCTGGTCCT...… |
The default behaviour is to mask the D region with Ns with option.
pp.quantify_mutations
The options for pp.quantify_mutations are the same as the basic mutational load analysis vignette [Gupta2015]. The default behavior is to sum all mutations scores (heavy and light chains, silent and replacement mutations) for the same cell.
Again, this function can be run immediately after pp.reassign_alleles on the genotyped .tsv files (without loading into pandas or Dandelion). Here I’m illustrating a few other options that may be useful.
[10]:
# switching back to using the full vdj object
ddl.pp.quantify_mutations(vdj)
Quantifying mutations
finished: Updated Dandelion object:
'data', contig-indexed AIRR table
'metadata', cell-indexed observations table
(0:00:12)
[11]:
ddl.pp.quantify_mutations(vdj, combine=False)
Quantifying mutations
finished: Updated Dandelion object:
'data', contig-indexed AIRR table
'metadata', cell-indexed observations table
(0:00:05)
Specifying split_locus = True will split up the results for the different chains.
[12]:
ddl.pp.quantify_mutations(vdj, split_locus=True)
Quantifying mutations
finished: Updated Dandelion object:
'data', contig-indexed AIRR table
'metadata', cell-indexed observations table
(0:00:06)
To update the AnnData object, simply rerun tl.transfer.
[13]:
ddl.tl.transfer(adata, vdj)
Transferring network
finished: updated `.obs` with `.metadata`
wrote active layout to `.obsm['X_vdj']`; stashed all views in `.uns['dandelion']` ('X_vdj_all', 'X_vdj_expanded')
wrote `.obsp['connectivities']` & `['distances']` from graph[0]
stashed GEX matrices in `.uns['dandelion']` ('gex_connectivities', 'gex_distances')
stashed VDJ matrices in `.uns['dandelion']` under 'vdj_connectivities_all' / '_expanded'
added `.uns['clone_id']` clone-level mapping (0:00:00)
[14]:
adata
[14]:
AnnData object with n_obs × n_vars = 25063 × 1309
obs: 'sample_id', 'n_genes', 'n_genes_by_counts', 'total_counts', 'total_counts_mt', 'pct_counts_mt', 'gmm_pct_count_clusters_keep', 'scrublet_score', 'is_doublet', 'filter_rna', 'has_contig', 'productive_VDJ', 'productive_VJ', 'd_call_VDJ', 'j_call_VDJ', 'j_call_VJ', 'junction_VDJ', 'junction_VJ', 'junction_aa_VDJ', 'junction_aa_VJ', 'locus_VDJ', 'locus_VJ', 'v_call_VDJ', 'v_call_VJ', 'c_call_VDJ', 'c_call_VJ', 'umi_count_VDJ', 'umi_count_VJ', 'productive_VDJ_main', 'productive_VJ_main', 'd_call_VDJ_main', 'j_call_VDJ_main', 'j_call_VJ_main', 'junction_VDJ_main', 'junction_VJ_main', 'junction_aa_VDJ_main', 'junction_aa_VJ_main', 'locus_VDJ_main', 'locus_VJ_main', 'v_call_genotyped_VDJ_main', 'v_call_genotyped_VJ_main', 'c_call_VDJ_main', 'c_call_VJ_main', 'umi_count_VDJ_main', 'umi_count_VJ_main', 'isotype', 'isotype_main', 'isotype_status', 'locus_status', 'chain_status', 'rearrangement_status_VDJ', 'rearrangement_status_VJ', 'leiden', 'clone_id', 'clone_id_rank', 'mu_count', 'mu_count_seq_r', 'mu_count_seq_s', 'mu_count_seq_r_IGH', 'mu_count_seq_s_IGH', 'mu_count_IGH', 'mu_count_seq_r_IGL', 'mu_count_seq_s_IGL', 'mu_count_IGL', 'mu_count_seq_r_IGK', 'mu_count_seq_s_IGK', 'mu_count_IGK'
var: 'n_cells', 'highly_variable', 'means', 'dispersions', 'dispersions_norm', 'mean', 'std'
uns: 'chain_status_colors', 'clone_id', 'dandelion', 'gex_neighbors', 'hvg', 'isotype_status_colors', 'leiden', 'leiden_colors', 'locus_status_colors', 'log1p', 'neighbors', 'pca', 'sample_id_colors', 'umap'
obsm: 'X_pca', 'X_umap', 'X_vdj'
varm: 'PCs'
obsp: 'connectivities', 'distances'
[15]:
from scanpy.plotting.palettes import default_28, default_102
sc.set_figure_params(figsize=[4, 4])
ddl.pl.clone_network(
adata,
color=[
"clone_id",
"mu_count",
"mu_count_seq_r",
"mu_count_seq_s",
"mu_count_IGH",
"mu_count_IGL",
],
ncols=2,
legend_loc="none",
legend_fontoutline=3,
edges_width=1,
palette=default_28 + default_102,
color_map="viridis",
size=20,
)
WARNING: Length of palette colors is smaller than the number of categories (palette length: 130, categories length: 2264. Some categories will have the same color.

Calculating diversity
ddl.tl.clone_rarefaction
We can use ddl.tl.clone_rarefaction to generate rarefaction curves for the clones. Here, I am grouping by sampleid in the AnnData object. The function will work on both AnnData and Dandelion objects. We fit the rarefaction curves using a Michaelis–Menten model and extrapolate them beyond the observed data points, with the asymptote providing an estimate of the expected number of unique clones at larger sample sizes.
[16]:
ddl.tl.clone_rarefaction(adata, group_by="sample_id", plot=True)
Calculating rarefaction + extrapolation: 100%|██████████| 4/4 [00:00<00:00, 8.47it/s]

You can also use it to return the results without plotting:
[17]:
pred = ddl.tl.clone_rarefaction(adata, group_by="sample_id", plot=False)
pred
Calculating rarefaction + extrapolation: 100%|██████████| 4/4 [00:00<00:00, 8.24it/s]
[17]:
| cells | yhat | group | type | plateau | |
|---|---|---|---|---|---|
| 0 | 1 | 1.000089 | sc5p_v2_hs_PBMC_1k_b | observed | 4628.762094 |
| 1 | 2 | 1.999767 | sc5p_v2_hs_PBMC_1k_b | observed | 4628.762094 |
| 2 | 3 | 2.999035 | sc5p_v2_hs_PBMC_1k_b | observed | 4628.762094 |
| 3 | 4 | 3.997893 | sc5p_v2_hs_PBMC_1k_b | observed | 4628.762094 |
| 4 | 5 | 4.996342 | sc5p_v2_hs_PBMC_1k_b | observed | 4628.762094 |
| ... | ... | ... | ... | ... | ... |
| 47051 | 14555 | 12781.469004 | sc5p_v2_hs_PBMC_10k_b | extrapolated | 99629.276820 |
| 47052 | 14556 | 12782.240122 | sc5p_v2_hs_PBMC_10k_b | extrapolated | 99629.276820 |
| 47053 | 14557 | 12783.011227 | sc5p_v2_hs_PBMC_10k_b | extrapolated | 99629.276820 |
| 47054 | 14558 | 12783.782320 | sc5p_v2_hs_PBMC_10k_b | extrapolated | 99629.276820 |
| 47055 | 14559 | 12784.553399 | sc5p_v2_hs_PBMC_10k_b | extrapolated | 99629.276820 |
47056 rows × 5 columns
Let’s try and resample the data to a larger number of cells to see how many unique clones we would expect to see if we simulated to have more data.
[18]:
vdj_large = ddl.tl.vdj_sample(vdj_data=vdj, size=5000)
# re-run clone finding on the larger dataset
ddl.tl.find_clones(vdj_large)
ddl.tl.clone_rarefaction(
vdj_large,
group_by="sample_id",
plot=True,
palette=adata.uns["sample_id_colors"],
)
Resampling to 5000 cells.
Finding clonotypes
Using PyTorch backend with Apple Metal GPU
Finding clones based on B cell VDJ chains using junction_aa: 100%|██████████| 1148/1148 [00:00<00:00, 1518.98it/s]
Finding clones based on B cell VJ chains using junction_aa: 100%|██████████| 537/537 [00:00<00:00, 1227.90it/s]
Storing distance matrix...
Building distance matrix (batched): 100%|██████████| 17/17 [00:00<00:00, 2207.19it/s]
Stored distances as CSR sparse matrix: (4985, 4985), density=0.57%
finished: Updated Dandelion object:
'data', contig AIRR table
'metadata', cell observations table
'distances', sparse distance matrix
(0:00:01)
Calculating rarefaction + extrapolation: 100%|██████████| 4/4 [00:00<00:00, 5.66it/s]

ddl.tl.clone_diversity
ddl.tl.clone_diversity allows for calculation of diversity measures such as Chao1, Shannon Entropy and Gini indices.
For Gini indices, we provide several types of measures, inspired by bulk BCRseq analysis methods from [Bashford-Rogers2013]:
The following two indices are returned with network_metric="clone_network".
network cluster/clone size Gini index
In a contracted BCR network (where identical BCRs are collapsed into the same node/vertex), disparity in the distribution should be correlated to the amount of mutation events i.e. larger networks should indicate more mutation events and smaller networks should indicate lesser mutation events.
network vertex/node size Gini index
In the same contracted network, we can count the number of merged/contracted nodes; nodes with higher count numbers indicate more clonal expansion. Thus, disparity in the distribution of count numbers (referred to as vertex size) should be correlated to the overall clonality i.e. clones with larger vertex sizes are more monoclonal and clones with smaller vertex sizes are more polyclonal.
Therefore, a Gini index of 1 on either measures repesents perfect inequality (i.e. monoclonal and highly mutated) and a value of 0 represents perfect equality (i.e. polyclonal and unmutated).
Note
However, there are a few limitations/challenges that comes with single-cell data:
In the process of contracting the network, we discard the single-cell level information.
Contraction of network is very slow, particularly when there is a lot of clonally-related cells.
For the full implementation and interpretation of both measures, although more evident with cluster/clone size, it requires the BCR repertoire to be reasonably/deeply sampled and we know that this is currently limited by the low recovery from single cell data with current technologies.
Therefore, we implement a few work around options, and ‘experimental’ options below, to try and circumvent these issues.
Firstly, as a work around for (C), the cluster size gini index can be calculated before or after network contraction. If performing before network contraction (default), it will be calculated based on the size of subgraphs of connected components in the main graph. This will retain the single-cell information and should appropriately show the distribution of the data. If performing after network contraction, the calculation is performed after network contraction, achieving the same effect as the
method for bulk BCR-seq as described above. This option can be toggled by use_contracted and only applies to network cluster size gini index calculation.
clone centrality Gini index -
network_metric="clone_centrality"
Node/vertex closeness centrality indicates how tightly packed clones are (more clonally related) and thus the distribution of the number of cells connected in each clone informs on whether clones in general are more monoclonal or polyclonal.
clone degree Gini index -
network_metric="clone_degree"
Node/vertex degree indicates how many cells are connected to an individual cell, another indication of how clonally related cells are. However, this would also highlight cells that are in the middle of large networks but are not necessarily within clonally expanded regions (e.g. intermediate connecting cells within the minimum spanning tree).
clone size Gini index -
network_metric="clone_size"
This is not to be confused with the network cluster size gini index calculation above as this doesn’t rely on the network, although the values should be similar. This is just a simple implementation based on the data frame for the relevant clone_id column. By default, this metric is also returned when running network_metric=clone_centrality or network_metric=clone_degree.
Note
For (I) and (II), we can specify expanded_only option to compute the statistic for all clones or expanded only clones. Unlike options (I) and (II), the current calculation for (III) and (IV) is largely influenced by the amount of expanded clones i.e. clones with at least 2 cells, and not affected by the number of singleton clones because singleton clones will have a value of 0 regardless.
All the diversity functions will perform bootstrap sampling with replacements to estimate confidence intervals.
[19]:
results, raw = ddl.tl.clone_diversity(
vdj,
group_by="sample_id",
method="gini",
network_metric="clone_network",
n_boot=200,
n_cpus=8,
verbose=True,
)
results
Calculating Gini indices
Bootstrapping... vdj_nextgem_hs_pbmc3_b: 100%|██████████| 200/200 [00:23<00:00, 8.62it/s]
Bootstrapping... sc5p_v2_hs_PBMC_10k_b: 100%|██████████| 200/200 [00:14<00:00, 14.26it/s]
Bootstrapping... vdj_v1_hs_pbmc3_b: 100%|██████████| 200/200 [00:12<00:00, 16.54it/s]
Bootstrapping... sc5p_v2_hs_PBMC_1k_b: 100%|██████████| 200/200 [00:12<00:00, 16.45it/s]
[19]:
{'cluster_size_gini': sample_id mean std lower_95 upper_95
0 vdj_nextgem_hs_pbmc3_b 0.075280 0.029375 0.027022 0.132450
1 sc5p_v2_hs_PBMC_10k_b 0.057947 0.023268 0.027022 0.102019
2 vdj_v1_hs_pbmc3_b 0.071063 0.025030 0.027022 0.119706
3 sc5p_v2_hs_PBMC_1k_b 0.257730 0.020856 0.217264 0.296711,
'vertex_size_gini': sample_id mean std lower_95 upper_95
0 vdj_nextgem_hs_pbmc3_b 0.006270 0.006503 0.000000 0.020548
1 sc5p_v2_hs_PBMC_10k_b 0.001221 0.003318 0.000000 0.010274
2 vdj_v1_hs_pbmc3_b 0.003489 0.006149 0.000000 0.018779
3 sc5p_v2_hs_PBMC_1k_b 0.054992 0.017579 0.020548 0.090020}
[20]:
# let's merge the two results dataframes for easier plotting
cluster_size = results["cluster_size_gini"][["sample_id", "mean"]]
vertex_size = results["vertex_size_gini"][["sample_id", "mean"]]
cluster_size.rename(columns={"mean": "cluster_size_gini"}, inplace=True)
vertex_size.rename(columns={"mean": "vertex_size_gini"}, inplace=True)
combined_results = pd.concat(
[cluster_size.set_index("sample_id"), vertex_size.set_index("sample_id")],
axis=1,
)
# set the colours
palette = dict(
zip(adata.obs["sample_id"].cat.categories, adata.uns["sample_id_colors"])
)
p = sns.scatterplot(
x="cluster_size_gini",
y="vertex_size_gini",
data=combined_results,
hue=combined_results.index,
palette=palette,
)
p.set(ylim=(-0.1, 1), xlim=(-0.1, 1))
plt.legend(bbox_to_anchor=(1, 0.5), loc="center left", frameon=False)
plt.show()

We can also plot the raw bootstrapped distributions for each sample to visualise the spread of the values.
[21]:
fig, axes = plt.subplots(2, 2, figsize=(8, 8)) # 1 row, 2 columns
sns.histplot(
data=raw["cluster_size_gini"],
palette=palette,
ax=axes[0, 0],
)
sns.histplot(
data=raw["vertex_size_gini"],
palette=palette,
ax=axes[0, 1],
)
sns.boxplot(
data=raw["cluster_size_gini"],
palette=palette,
ax=axes[1, 0],
)
sns.boxplot(
data=raw["vertex_size_gini"],
palette=palette,
ax=axes[1, 1],
)
axes[0, 0].set_title("Cluster Size Gini")
axes[0, 1].set_title("Vertex Size Gini")
axes[0, 0].legend_.remove()
axes[0, 0].set_xlabel("Gini")
axes[0, 1].set_xlabel("Gini")
axes[1, 0].set_ylabel("Gini")
axes[1, 1].set_ylabel("Gini")
axes[1, 0].set_xticklabels(axes[1, 0].get_xticklabels(), rotation=90)
axes[1, 1].set_xticklabels(axes[1, 1].get_xticklabels(), rotation=90)
plt.tight_layout()
plt.show()

With these particular samples, because there is not many expanded clones in general, the gini indices are quite low when calculated within each sample. Let’s try and simulate a really large number of cells.
[22]:
# now let's create a large sample using vdj_sample with probability weighting based on the clone size proportions so that larger clones are more likely to be sampled
ddl.tl.clone_size(vdj)
# let's materialize the vdj object to be eager so that we can use it for sampling with probabilities
vdj.to_eager()
vdj_large = ddl.tl.vdj_sample(
vdj_data=vdj,
size=10000,
p=vdj.metadata["clone_id_size_prop"],
random_state=42,
)
vdj_large
Resampling to 10000 cells.
[22]:
Lazy Dandelion object with n_obs = 10000 and n_contigs = 16279
data: sequence_id, sequence, rev_comp, productive, v_call, d_call, j_call, sequence_alignment, germline_alignment, junction, junction_aa, v_cigar, d_cigar, j_cigar, stop_codon, vj_in_frame, locus, junction_length, np1_length, np2_length, v_sequence_start, v_sequence_end, v_germline_start, v_germline_end, d_sequence_start, d_sequence_end, d_germline_start, d_germline_end, j_sequence_start, j_sequence_end, j_germline_start, j_germline_end, v_score, v_identity, v_support, d_score, d_identity, d_support, j_score, j_identity, j_support, fwr1, fwr2, fwr3, fwr4, cdr1, cdr2, cdr3, cell_id, consensus_count, umi_count, v_call_10x, d_call_10x, j_call_10x, junction_10x, junction_10x_aa, j_call_blastn, j_identity_blastn, j_alignment_length_blastn, j_number_of_mismatches_blastn, j_number_of_gap_openings_blastn, j_sequence_start_blastn, j_sequence_end_blastn, j_germline_start_blastn, j_germline_end_blastn, j_support_blastn, j_score_blastn, j_sequence_alignment_blastn, j_germline_alignment_blastn, j_call_igblastn, j_source, j_support_igblastn, j_score_igblastn, d_call_blastn, d_identity_blastn, d_alignment_length_blastn, d_number_of_mismatches_blastn, d_number_of_gap_openings_blastn, d_sequence_start_blastn, d_sequence_end_blastn, d_germline_start_blastn, d_germline_end_blastn, d_support_blastn, d_score_blastn, d_sequence_alignment_blastn, d_germline_alignment_blastn, d_call_igblastn, d_source, d_support_igblastn, d_score_igblastn, v_call_genotyped, germline_alignment_d_mask, sample_id, c_call, c_sequence_alignment, c_germline_alignment, c_sequence_start, c_sequence_end, c_score, c_identity, c_call_10x, junction_aa_length, fwr1_aa, fwr2_aa, fwr3_aa, fwr4_aa, cdr1_aa, cdr2_aa, cdr3_aa, sequence_alignment_aa, v_sequence_alignment_aa, d_sequence_alignment_aa, j_sequence_alignment_aa, complete_vdj, j_call_multimappers, j_call_multiplicity, j_call_sequence_start_multimappers, j_call_sequence_end_multimappers, j_call_support_multimappers, rearrangement_status, v_call_functionality, d_call_functionality, j_call_functionality, extra, ambiguous, clone_id, mu_count_seq_r, mu_count_seq_s, mu_count
metadata: cell_id, clone_id, clone_id_rank, sample_id, productive_VDJ, productive_VJ, d_call_VDJ, j_call_VDJ, j_call_VJ, junction_VDJ, junction_VJ, junction_aa_VDJ, junction_aa_VJ, locus_VDJ, locus_VJ, v_call_VDJ, v_call_VJ, c_call_VDJ, c_call_VJ, umi_count_VDJ, umi_count_VJ, productive_VDJ_main, productive_VJ_main, d_call_VDJ_main, j_call_VDJ_main, j_call_VJ_main, junction_VDJ_main, junction_VJ_main, junction_aa_VDJ_main, junction_aa_VJ_main, locus_VDJ_main, locus_VJ_main, v_call_genotyped_VDJ_main, v_call_genotyped_VJ_main, c_call_VDJ_main, c_call_VJ_main, umi_count_VDJ_main, umi_count_VJ_main, isotype, isotype_main, isotype_status, locus_status, chain_status, rearrangement_status_VDJ, rearrangement_status_VJ
Let’s also go a bit further and introduce some mutations into the sequences to see how that affects the diversity measures.
[23]:
from Bio.Seq import Seq
import random
NUCLEOTIDES = ["A", "T", "C", "G"]
GAP_CHARS = {".", "-", "N"}
def mutate_sequence(seq, mutation_rate=0.01):
"""Randomly mutate nucleotide sequence but skip gap characters."""
seq_list = list(seq)
for i, nt in enumerate(seq_list):
# Skip gaps or unknown characters
if nt.upper() not in NUCLEOTIDES:
continue
if random.random() < mutation_rate:
seq_list[i] = random.choice(
[n for n in NUCLEOTIDES if n != nt.upper()]
)
return "".join(seq_list)
def translate_cleaned_nt(seq):
"""Remove gap characters and translate clean nucleotide sequence."""
cleaned = "".join([nt for nt in seq if nt.upper() in NUCLEOTIDES])
return str(Seq(cleaned).translate(to_stop=False))
def mutate_dataframe(df, nt_col="junction", mutation_rate=0.01):
"""Mutate nucleotide sequences in the polars DataFrame and update amino acids."""
aa_col = nt_col + "_aa"
return df.with_columns(
pl.col(nt_col)
.map_elements(
lambda seq: mutate_sequence(seq, mutation_rate),
return_dtype=pl.Utf8,
)
.alias(nt_col),
).with_columns(
pl.col(nt_col)
.map_elements(translate_cleaned_nt, return_dtype=pl.Utf8)
.alias(aa_col),
)
[24]:
# convert to eager again
vdj_large.to_eager()
mut_df = mutate_dataframe(
vdj_large.data, nt_col="sequence_alignment", mutation_rate=0.01
)
vdj_large = ddl.Dandelion(mut_df)
vdj_large
[24]:
Lazy Dandelion object with n_obs = 10000 and n_contigs = 16279
data: sequence_id, sequence, rev_comp, productive, v_call, d_call, j_call, sequence_alignment, germline_alignment, junction, junction_aa, v_cigar, d_cigar, j_cigar, stop_codon, vj_in_frame, locus, junction_length, np1_length, np2_length, v_sequence_start, v_sequence_end, v_germline_start, v_germline_end, d_sequence_start, d_sequence_end, d_germline_start, d_germline_end, j_sequence_start, j_sequence_end, j_germline_start, j_germline_end, v_score, v_identity, v_support, d_score, d_identity, d_support, j_score, j_identity, j_support, fwr1, fwr2, fwr3, fwr4, cdr1, cdr2, cdr3, cell_id, consensus_count, umi_count, v_call_10x, d_call_10x, j_call_10x, junction_10x, junction_10x_aa, j_call_blastn, j_identity_blastn, j_alignment_length_blastn, j_number_of_mismatches_blastn, j_number_of_gap_openings_blastn, j_sequence_start_blastn, j_sequence_end_blastn, j_germline_start_blastn, j_germline_end_blastn, j_support_blastn, j_score_blastn, j_sequence_alignment_blastn, j_germline_alignment_blastn, j_call_igblastn, j_source, j_support_igblastn, j_score_igblastn, d_call_blastn, d_identity_blastn, d_alignment_length_blastn, d_number_of_mismatches_blastn, d_number_of_gap_openings_blastn, d_sequence_start_blastn, d_sequence_end_blastn, d_germline_start_blastn, d_germline_end_blastn, d_support_blastn, d_score_blastn, d_sequence_alignment_blastn, d_germline_alignment_blastn, d_call_igblastn, d_source, d_support_igblastn, d_score_igblastn, v_call_genotyped, germline_alignment_d_mask, sample_id, c_call, c_sequence_alignment, c_germline_alignment, c_sequence_start, c_sequence_end, c_score, c_identity, c_call_10x, junction_aa_length, fwr1_aa, fwr2_aa, fwr3_aa, fwr4_aa, cdr1_aa, cdr2_aa, cdr3_aa, sequence_alignment_aa, v_sequence_alignment_aa, d_sequence_alignment_aa, j_sequence_alignment_aa, complete_vdj, j_call_multimappers, j_call_multiplicity, j_call_sequence_start_multimappers, j_call_sequence_end_multimappers, j_call_support_multimappers, rearrangement_status, v_call_functionality, d_call_functionality, j_call_functionality, extra, ambiguous, clone_id, mu_count_seq_r, mu_count_seq_s, mu_count
metadata: cell_id, clone_id, clone_id_rank, sample_id, productive_VDJ, productive_VJ, d_call_VDJ, j_call_VDJ, j_call_VJ, junction_VDJ, junction_VJ, junction_aa_VDJ, junction_aa_VJ, locus_VDJ, locus_VJ, v_call_VDJ, v_call_VJ, c_call_VDJ, c_call_VJ, umi_count_VDJ, umi_count_VJ, productive_VDJ_main, productive_VJ_main, d_call_VDJ_main, j_call_VDJ_main, j_call_VJ_main, junction_VDJ_main, junction_VJ_main, junction_aa_VDJ_main, junction_aa_VJ_main, locus_VDJ_main, locus_VJ_main, v_call_genotyped_VDJ_main, v_call_genotyped_VJ_main, c_call_VDJ_main, c_call_VJ_main, umi_count_VDJ_main, umi_count_VJ_main, isotype, isotype_main, isotype_status, locus_status, chain_status, rearrangement_status_VDJ, rearrangement_status_VJ
[25]:
# let's make an adata_large object with the same cells as vdj_large but with the same gene expression data as adata for easier comparison
adata_large = sc.AnnData(
obs=vdj_large.metadata.collect().to_pandas().set_index("cell_id")
)
adata_large
[25]:
AnnData object with n_obs × n_vars = 10000 × 0
obs: 'clone_id', 'clone_id_rank', 'sample_id', 'productive_VDJ', 'productive_VJ', 'd_call_VDJ', 'j_call_VDJ', 'j_call_VJ', 'junction_VDJ', 'junction_VJ', 'junction_aa_VDJ', 'junction_aa_VJ', 'locus_VDJ', 'locus_VJ', 'v_call_VDJ', 'v_call_VJ', 'c_call_VDJ', 'c_call_VJ', 'umi_count_VDJ', 'umi_count_VJ', 'productive_VDJ_main', 'productive_VJ_main', 'd_call_VDJ_main', 'j_call_VDJ_main', 'j_call_VJ_main', 'junction_VDJ_main', 'junction_VJ_main', 'junction_aa_VDJ_main', 'junction_aa_VJ_main', 'locus_VDJ_main', 'locus_VJ_main', 'v_call_genotyped_VDJ_main', 'v_call_genotyped_VJ_main', 'c_call_VDJ_main', 'c_call_VJ_main', 'umi_count_VDJ_main', 'umi_count_VJ_main', 'isotype', 'isotype_main', 'isotype_status', 'locus_status', 'chain_status', 'rearrangement_status_VDJ', 'rearrangement_status_VJ'
[26]:
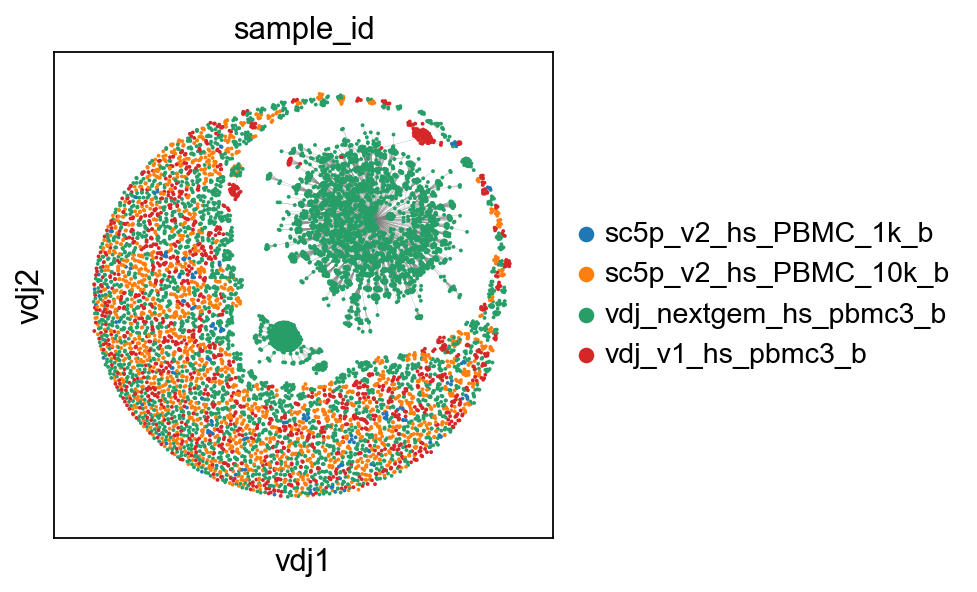
# what does this dataset look like?
ddl.tl.generate_network(vdj_large, use_existing_graph=False)
ddl.tl.transfer(adata_large, vdj_large)
ddl.pl.clone_network(adata_large, color=["sample_id"])
Generating network
Calculating distance matrix with distance_mode = 'clone'
100%|██████████| 2056/2056 [03:13<00:00, 10.63it/s]
Distances calculated in 193.67 seconds
Computing network layout
Computing expanded network layout
finished.
Updated Dandelion object
: 'layout', graph layout
(0:03:31)
Transferring network
finished: updated `.obs` with `.metadata`
wrote active layout to `.obsm['X_vdj']`; stashed all views in `.uns['dandelion']` ('X_vdj_all', 'X_vdj_expanded')
wrote `.obsp['connectivities']` & `['distances']` from graph[0]
stashed VDJ matrices in `.uns['dandelion']` under 'vdj_connectivities_all' / '_expanded'
added `.uns['clone_id']` clone-level mapping (0:00:01)
[27]:
results, raw = ddl.tl.clone_diversity(
vdj_large,
group_by="sample_id",
method="gini",
network_metric="clone_network",
n_boot=200,
n_cpus=8,
verbose=True,
)
results
Calculating Gini indices
Bootstrapping... vdj_nextgem_hs_pbmc3_b: 100%|██████████| 200/200 [01:02<00:00, 3.19it/s]
Bootstrapping... sc5p_v2_hs_PBMC_10k_b: 100%|██████████| 200/200 [00:27<00:00, 7.25it/s]
Bootstrapping... vdj_v1_hs_pbmc3_b: 100%|██████████| 200/200 [00:36<00:00, 5.46it/s]
Bootstrapping... sc5p_v2_hs_PBMC_1k_b: 100%|██████████| 200/200 [00:32<00:00, 6.13it/s]
[27]:
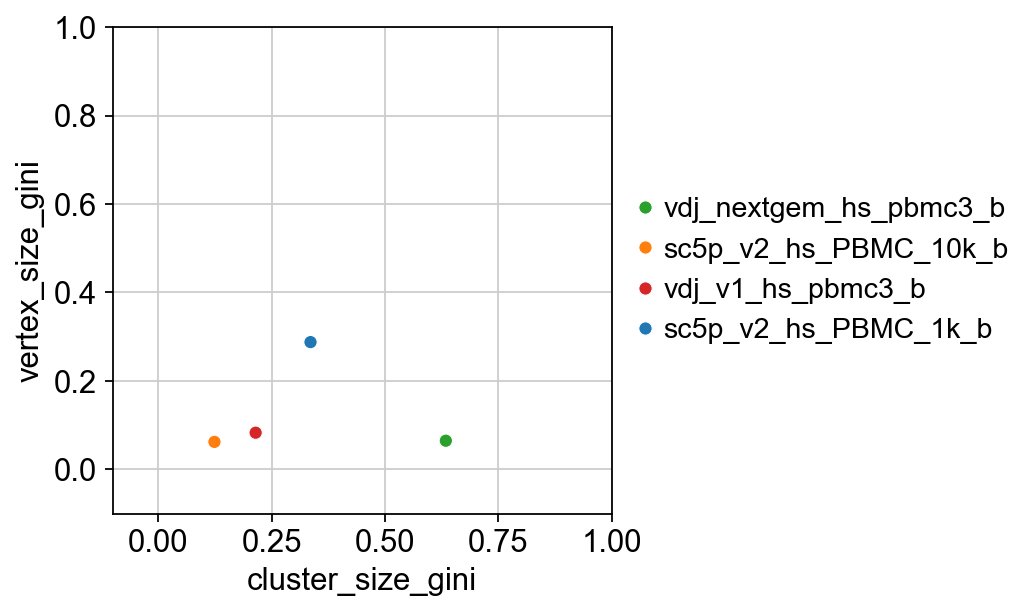
{'cluster_size_gini': sample_id mean std lower_95 upper_95
0 vdj_nextgem_hs_pbmc3_b 0.629206 0.033964 0.564067 0.696200
1 sc5p_v2_hs_PBMC_10k_b 0.130583 0.018577 0.101302 0.169663
2 vdj_v1_hs_pbmc3_b 0.216369 0.024876 0.170762 0.261390
3 sc5p_v2_hs_PBMC_1k_b 0.330520 0.021859 0.292209 0.377758,
'vertex_size_gini': sample_id mean std lower_95 upper_95
0 vdj_nextgem_hs_pbmc3_b 0.067564 0.017565 0.034725 0.100531
1 sc5p_v2_hs_PBMC_10k_b 0.067095 0.014655 0.042433 0.100534
2 vdj_v1_hs_pbmc3_b 0.086690 0.015559 0.056678 0.118070
3 sc5p_v2_hs_PBMC_1k_b 0.286548 0.018872 0.253434 0.322666}
[28]:
# let's merge the two results dataframes for easier plotting
cluster_size = results["cluster_size_gini"][["sample_id", "mean"]]
vertex_size = results["vertex_size_gini"][["sample_id", "mean"]]
cluster_size.rename(columns={"mean": "cluster_size_gini"}, inplace=True)
vertex_size.rename(columns={"mean": "vertex_size_gini"}, inplace=True)
combined_results = pd.concat(
[cluster_size.set_index("sample_id"), vertex_size.set_index("sample_id")],
axis=1,
)
# set the colours
palette = dict(
zip(adata.obs["sample_id"].cat.categories, adata.uns["sample_id_colors"])
)
p = sns.scatterplot(
x="cluster_size_gini",
y="vertex_size_gini",
data=combined_results,
hue=combined_results.index,
palette=palette,
)
p.set(ylim=(-0.1, 1), xlim=(-0.1, 1))
plt.legend(bbox_to_anchor=(1, 0.5), loc="center left", frameon=False)
plt.show()
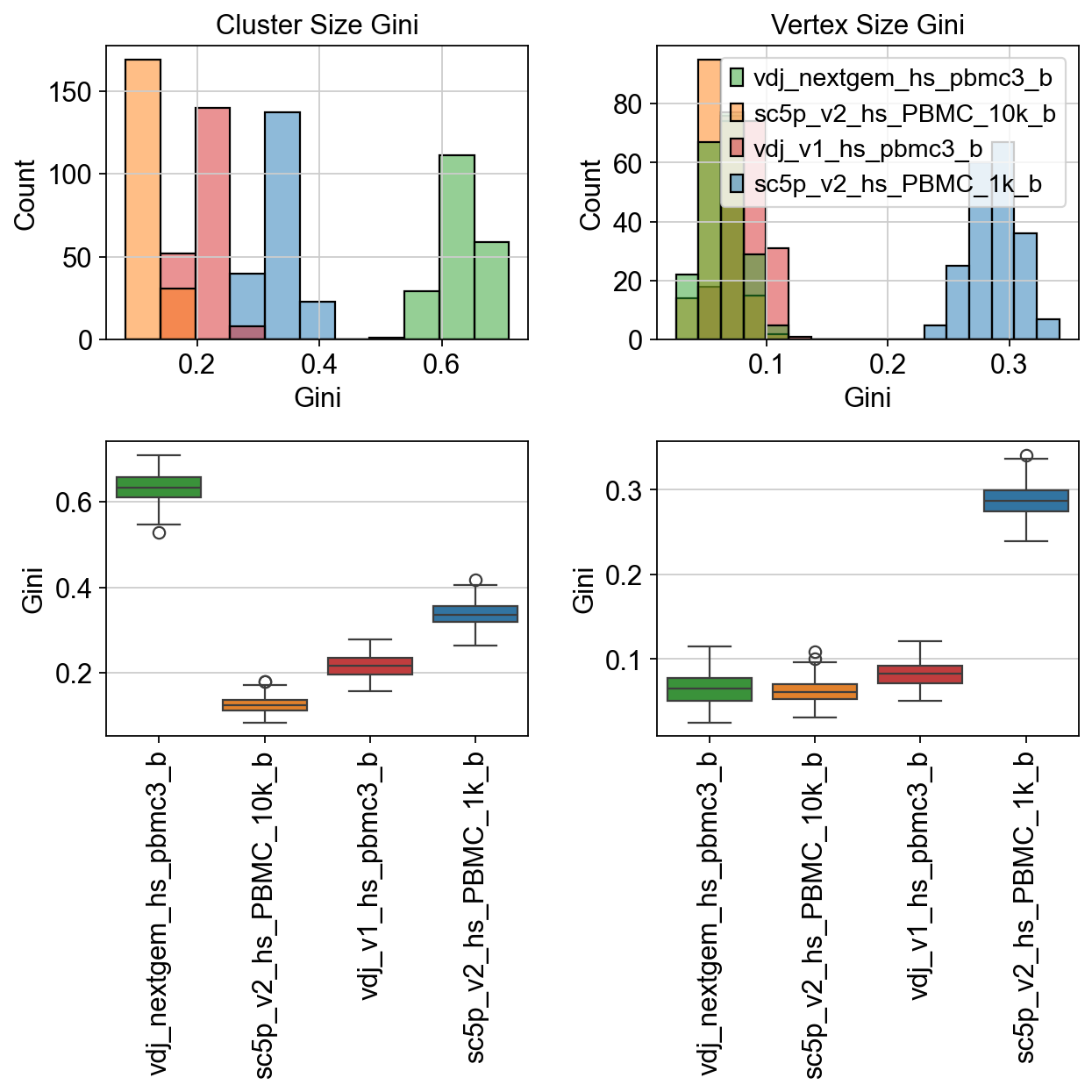
[29]:
fig, axes = plt.subplots(2, 2, figsize=(8, 8)) # 1 row, 2 columns
sns.histplot(
data=raw["cluster_size_gini"],
palette=palette,
ax=axes[0, 0],
)
sns.histplot(
data=raw["vertex_size_gini"],
palette=palette,
ax=axes[0, 1],
)
sns.boxplot(
data=raw["cluster_size_gini"],
palette=palette,
ax=axes[1, 0],
)
sns.boxplot(
data=raw["vertex_size_gini"],
palette=palette,
ax=axes[1, 1],
)
axes[0, 0].set_title("Cluster Size Gini")
axes[0, 1].set_title("Vertex Size Gini")
axes[0, 0].legend_.remove()
axes[0, 0].set_xlabel("Gini")
axes[0, 1].set_xlabel("Gini")
axes[1, 0].set_ylabel("Gini")
axes[1, 1].set_ylabel("Gini")
axes[1, 0].set_xticklabels(axes[1, 0].get_xticklabels(), rotation=90)
axes[1, 1].set_xticklabels(axes[1, 1].get_xticklabels(), rotation=90)
plt.tight_layout()
plt.show()
Now using network_metric = "clone_centrality":
[30]:
results, raw = ddl.tl.clone_diversity(
vdj_large,
group_by="sample_id",
method="gini",
network_metric="clone_network",
n_boot=200,
n_cpus=8,
verbose=True,
)
results
Calculating Gini indices
Bootstrapping... vdj_nextgem_hs_pbmc3_b: 100%|██████████| 200/200 [01:00<00:00, 3.30it/s]
Bootstrapping... sc5p_v2_hs_PBMC_10k_b: 100%|██████████| 200/200 [00:26<00:00, 7.50it/s]
Bootstrapping... vdj_v1_hs_pbmc3_b: 100%|██████████| 200/200 [00:24<00:00, 8.03it/s]
Bootstrapping... sc5p_v2_hs_PBMC_1k_b: 100%|██████████| 200/200 [00:18<00:00, 11.07it/s]
[30]:
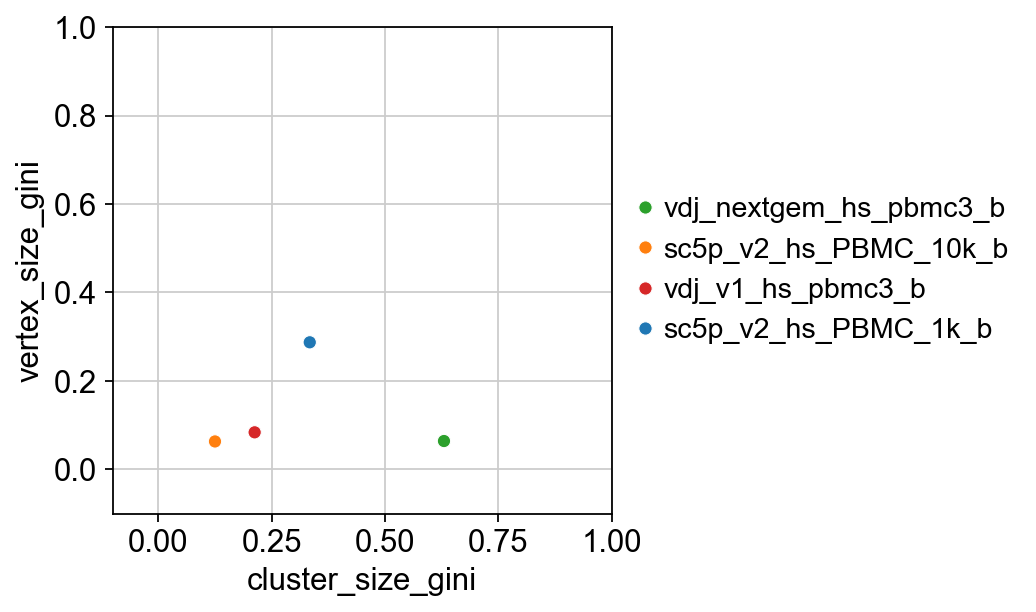
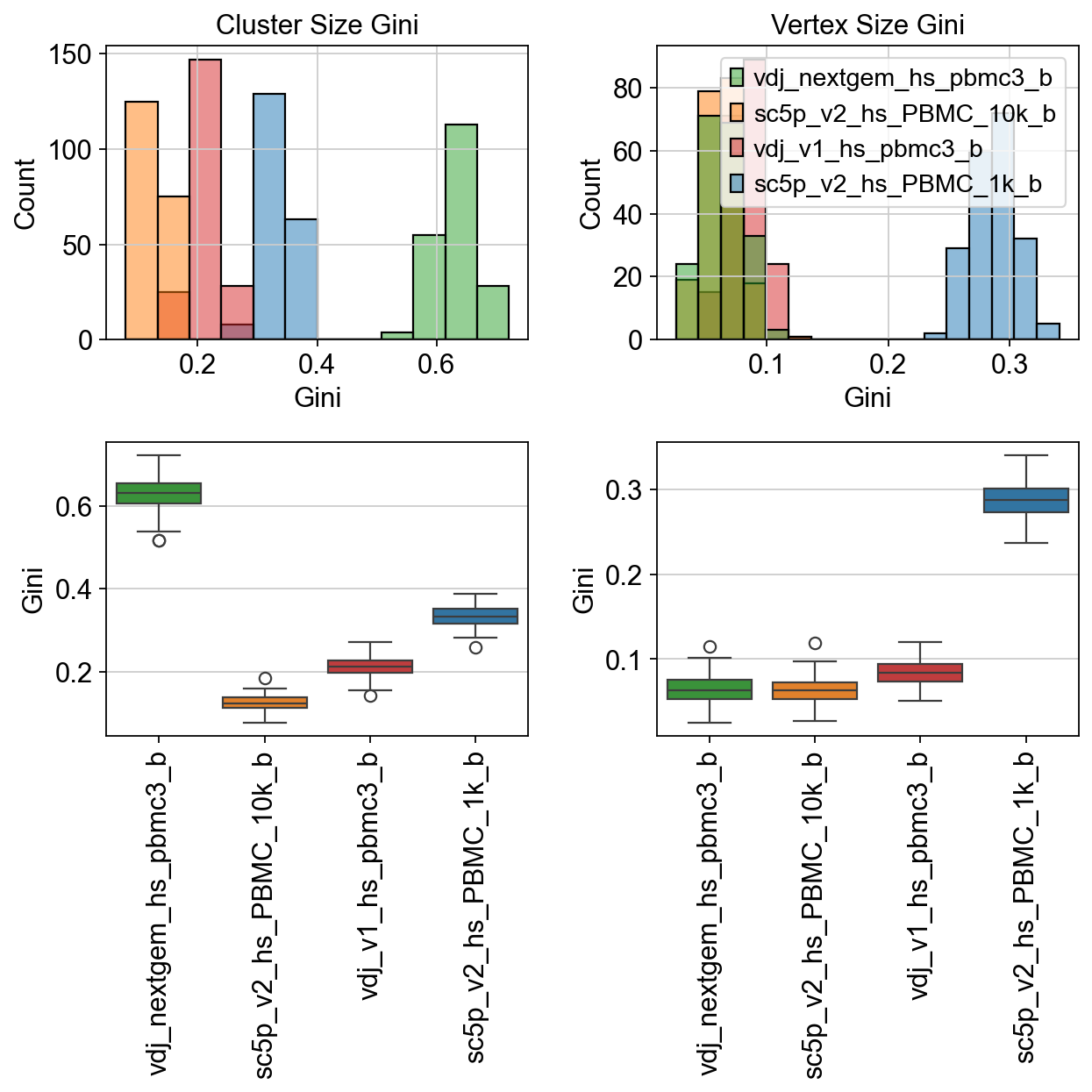
{'cluster_size_gini': sample_id mean std lower_95 upper_95
0 vdj_nextgem_hs_pbmc3_b 0.635658 0.037093 0.551273 0.701394
1 sc5p_v2_hs_PBMC_10k_b 0.129562 0.017749 0.096342 0.163165
2 vdj_v1_hs_pbmc3_b 0.216619 0.024706 0.178674 0.269425
3 sc5p_v2_hs_PBMC_1k_b 0.328155 0.025540 0.275662 0.367883,
'vertex_size_gini': sample_id mean std lower_95 upper_95
0 vdj_nextgem_hs_pbmc3_b 0.069306 0.017584 0.036448 0.101616
1 sc5p_v2_hs_PBMC_10k_b 0.065286 0.015180 0.041602 0.095846
2 vdj_v1_hs_pbmc3_b 0.087948 0.014626 0.061207 0.118407
3 sc5p_v2_hs_PBMC_1k_b 0.289226 0.019207 0.253578 0.330002}
[31]:
# let's merge the two results dataframes for easier plotting
cluster_size = results["cluster_size_gini"][["sample_id", "mean"]]
vertex_size = results["vertex_size_gini"][["sample_id", "mean"]]
cluster_size.rename(columns={"mean": "cluster_size_gini"}, inplace=True)
vertex_size.rename(columns={"mean": "vertex_size_gini"}, inplace=True)
combined_results = pd.concat(
[cluster_size.set_index("sample_id"), vertex_size.set_index("sample_id")],
axis=1,
)
# set the colours
palette = dict(
zip(adata.obs["sample_id"].cat.categories, adata.uns["sample_id_colors"])
)
p = sns.scatterplot(
x="cluster_size_gini",
y="vertex_size_gini",
data=combined_results,
hue=combined_results.index,
palette=palette,
)
p.set(ylim=(-0.1, 1), xlim=(-0.1, 1))
plt.legend(bbox_to_anchor=(1, 0.5), loc="center left", frameon=False)
plt.show()
[32]:
fig, axes = plt.subplots(2, 2, figsize=(8, 8)) # 1 row, 2 columns
sns.histplot(
data=raw["cluster_size_gini"],
palette=palette,
ax=axes[0, 0],
)
sns.histplot(
data=raw["vertex_size_gini"],
palette=palette,
ax=axes[0, 1],
)
sns.boxplot(
data=raw["cluster_size_gini"],
palette=palette,
ax=axes[1, 0],
)
sns.boxplot(
data=raw["vertex_size_gini"],
palette=palette,
ax=axes[1, 1],
)
axes[0, 0].set_title("Cluster Size Gini")
axes[0, 1].set_title("Vertex Size Gini")
axes[0, 0].legend_.remove()
axes[0, 0].set_xlabel("Gini")
axes[0, 1].set_xlabel("Gini")
axes[1, 0].set_ylabel("Gini")
axes[1, 1].set_ylabel("Gini")
axes[1, 0].set_xticklabels(axes[1, 0].get_xticklabels(), rotation=90)
axes[1, 1].set_xticklabels(axes[1, 1].get_xticklabels(), rotation=90)
plt.tight_layout()
plt.show()
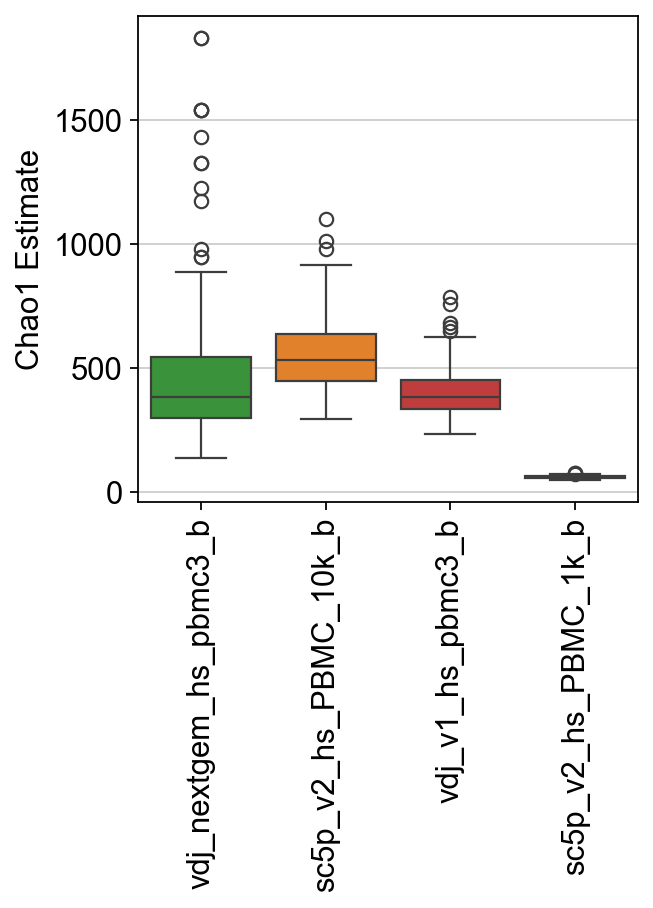
Finally, let’s try the other diversity methods. chao1 is an estimator based on abundance.
[33]:
results, raw = ddl.tl.clone_diversity(
vdj_large,
group_by="sample_id",
method="chao1",
n_boot=200,
n_cpus=8,
verbose=True,
)
results
Bootstrapping… vdj_nextgem_hs_pbmc3_b: 100%|██████████| 200/200 [00:00<00:00, 655.21it/s]
Bootstrapping… sc5p_v2_hs_PBMC_10k_b: 100%|██████████| 200/200 [00:00<00:00, 1732.71it/s]
Bootstrapping… vdj_v1_hs_pbmc3_b: 100%|██████████| 200/200 [00:00<00:00, 2083.71it/s]
Bootstrapping… sc5p_v2_hs_PBMC_1k_b: 100%|██████████| 200/200 [00:00<00:00, 5336.77it/s]
[33]:
{'chao1': sample_id mean std lower_95 upper_95
0 vdj_nextgem_hs_pbmc3_b 522.570857 327.578065 201.640714 1598.000000
1 sc5p_v2_hs_PBMC_10k_b 524.852516 111.582142 351.115385 789.000000
2 vdj_v1_hs_pbmc3_b 404.680823 104.815432 262.065000 666.812500
3 sc5p_v2_hs_PBMC_1k_b 62.683376 5.448758 54.116095 77.019231}
[34]:
ax = sns.boxplot(
data=raw["chao1"],
palette=palette,
)
ax.set_ylabel("Chao1 Estimate")
ax.set_xticklabels(ax.get_xticklabels(), rotation=90)
plt.show()
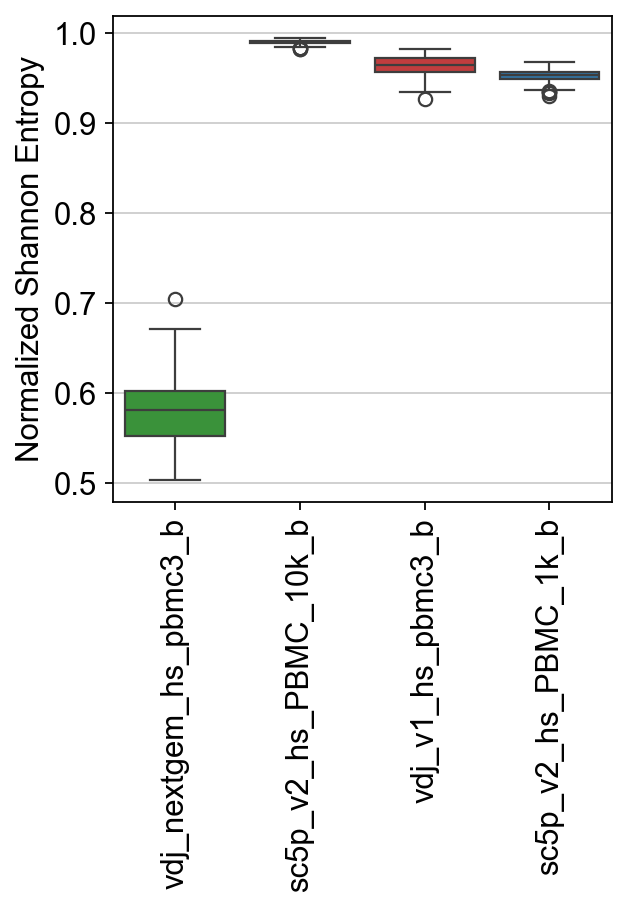
For Shannon Entropy, we can calculate a normalized (inspired by scirpy’s function) and non-normalized value.
[35]:
results, raw = ddl.tl.clone_diversity(
vdj_large,
group_by="sample_id",
method="shannon",
n_boot=200,
n_cpus=8,
verbose=True,
)
results
Bootstrapping… vdj_nextgem_hs_pbmc3_b: 100%|██████████| 200/200 [00:00<00:00, 299.63it/s]
Bootstrapping… sc5p_v2_hs_PBMC_10k_b: 100%|██████████| 200/200 [00:00<00:00, 1747.94it/s]
Bootstrapping… vdj_v1_hs_pbmc3_b: 100%|██████████| 200/200 [00:00<00:00, 1862.87it/s]
Bootstrapping… sc5p_v2_hs_PBMC_1k_b: 100%|██████████| 200/200 [00:00<00:00, 4439.03it/s]
[35]:
{'shannon': sample_id mean std lower_95 upper_95
0 vdj_nextgem_hs_pbmc3_b 0.582920 0.031647 0.520799 0.645746
1 sc5p_v2_hs_PBMC_10k_b 0.989319 0.002276 0.984269 0.993306
2 vdj_v1_hs_pbmc3_b 0.962700 0.009780 0.941955 0.979925
3 sc5p_v2_hs_PBMC_1k_b 0.953494 0.007328 0.939314 0.966651}
[36]:
ax = sns.boxplot(
data=raw["shannon"],
palette=palette,
)
ax.set_ylabel("Normalized Shannon Entropy")
ax.set_xticklabels(ax.get_xticklabels(), rotation=90)
plt.show()
[37]:
results, raw = ddl.tl.clone_diversity(
vdj_large,
group_by="sample_id",
method="shannon",
n_boot=200,
n_cpus=8,
verbose=True,
normalize=False,
)
results
Bootstrapping… vdj_nextgem_hs_pbmc3_b: 100%|██████████| 200/200 [00:00<00:00, 642.49it/s]
Bootstrapping… sc5p_v2_hs_PBMC_10k_b: 100%|██████████| 200/200 [00:00<00:00, 1787.93it/s]
Bootstrapping… vdj_v1_hs_pbmc3_b: 100%|██████████| 200/200 [00:00<00:00, 2074.66it/s]
Bootstrapping… sc5p_v2_hs_PBMC_1k_b: 100%|██████████| 200/200 [00:00<00:00, 4768.91it/s]
[37]:
{'shannon': sample_id mean std lower_95 upper_95
0 vdj_nextgem_hs_pbmc3_b 3.420267 0.284787 2.911771 3.981523
1 sc5p_v2_hs_PBMC_10k_b 7.019868 0.059896 6.902979 7.122005
2 vdj_v1_hs_pbmc3_b 6.678115 0.107329 6.475141 6.880097
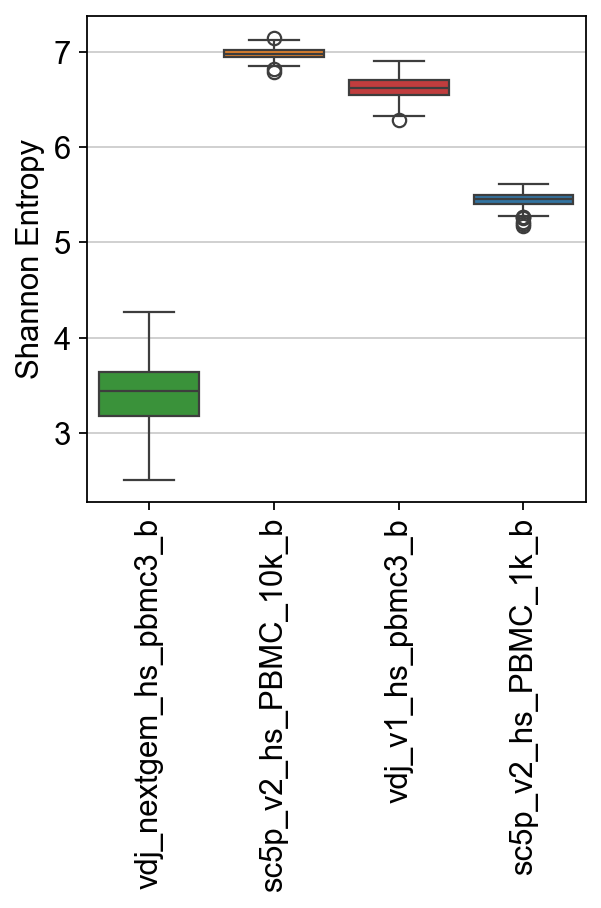
3 sc5p_v2_hs_PBMC_1k_b 5.506988 0.076159 5.317057 5.638655}
[38]:
ax = sns.boxplot(
data=raw["shannon"],
palette=palette,
)
ax.set_ylabel("Shannon Entropy")
ax.set_xticklabels(ax.get_xticklabels(), rotation=90)
plt.show()
There’s also a gini method that doesn’t require network construction, which should be faster to compute.
[39]:
results, raw = ddl.tl.clone_diversity(
vdj_large,
group_by="sample_id",
method="gini",
use_network=False,
n_boot=200,
n_cpus=8,
verbose=True,
)
results
Bootstrapping… vdj_nextgem_hs_pbmc3_b: 100%|██████████| 200/200 [00:00<00:00, 623.21it/s]
Bootstrapping… sc5p_v2_hs_PBMC_10k_b: 100%|██████████| 200/200 [00:00<00:00, 1760.72it/s]
Bootstrapping… vdj_v1_hs_pbmc3_b: 100%|██████████| 200/200 [00:00<00:00, 2148.67it/s]
Bootstrapping… sc5p_v2_hs_PBMC_1k_b: 100%|██████████| 200/200 [00:00<00:00, 4550.81it/s]
[39]:
{'gini': sample_id mean std lower_95 upper_95
0 vdj_nextgem_hs_pbmc3_b 0.627329 0.033230 0.565261 0.688682
1 sc5p_v2_hs_PBMC_10k_b 0.124054 0.018252 0.090191 0.163628
2 vdj_v1_hs_pbmc3_b 0.208604 0.024808 0.160419 0.254814
3 sc5p_v2_hs_PBMC_1k_b 0.329623 0.025618 0.279153 0.379480}
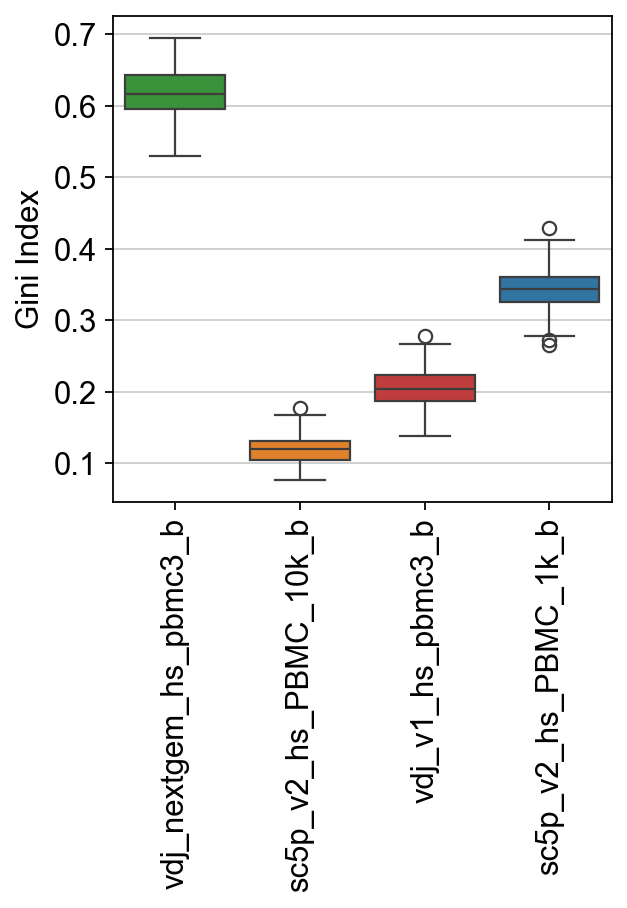
[40]:
ax = sns.boxplot(
data=raw["gini"],
palette=palette,
)
ax.set_ylabel("Gini Index")
ax.set_xticklabels(ax.get_xticklabels(), rotation=90)
plt.show()